01-2 데이터베이스의 종류
p.18 ~ 27
1. 계층형 데이터베이스
1)
계층형 데이터베이스는 데이터가 부모와 자식의 관계를 이루는 트리 구조 이다.
그래서,
부모 레코드(행, row, tuple) 가 여러 자식 레코드(행, row, tuple) 을 갖게 된다.
2)
계층형 데이터베이스는 데이터 중복이 발생하기 쉽다.
3)
데이터는 상하 종속 관계로 이루어지므로,
초기에 이 방식을 채택하면 이후 프로세스 변경이 어렵다.
4)
따라서 현재는 이 형식으로 데이터베이스를 거의 사용하지 않는다.
2. 네트워크형 데이터베이스
1)
네트워크형 데이터베이스는 데이터를 노드로 표현한 모델 이다.
노드는 네트워크상에 있으며, 서로 대등한 관계이다.
계층형 데이터베이스의 단점인
데이터 중복 문제 및 상하 종속 관계를 해결한 모델 이다.
2)
네트워크형 데이터베이스는 레코드(행, row, tuple) 간의 관계를
일대다 또는 다대다로 표현할 수 있지만, 서로간의 종속성 문제가 생기기 쉽다.
이말은 데이터베이스 구조를 변경하기 어렵다는 의미가 된다.
3. 키-값 데이터베이스
1)
키-값 데이터베이스 (key - value database) 는 NoSQL의 한 종류이다.
키-값을 일대일 대응하여 데이터를 저장 한다.
NoSQL이란 비관계형 데이터베이스를 가리킬 때 사용한다.
기존 관계형 데이터베이스의 한계를 극복하는 데이터 저장소로
도큐먼트, 그래프, 키-값, 검색 등 다양한 데이터 모델을 사용 한다.
2)
데이터 중복이 발생하여 비정형 데이터 저장에 유리한 방식 이다.
3)
비정형 데이터 (unstructured data) : 형식이 없는 데이터
텍스트, 음성, 영상과 같은 데이터가 비정형 데이터 범위에 속한다.
정형 데이터 (structured data) : 형식이 있는 데이터
데이터베이스의 정해진 규칙(rule) 에 맞게 데이터를 저장하며,
각 데이터는 열 이름 (칼럼명) 으로 의미를 쉽게 파악할 수 있다.
4)
키-값 데이터베이스는 관계형 데이터베이스와 함께 가장 많이 사용한다.
키-값 스토어 라고도 불린다.
키와 값을 한 쌍으로 해서 데이터를 저장하는 비관계형 데이터베이스 유형이다.
키-값 데이터베이스는 고유한 식별자로 사용하며,
단순한 객체에서 복잡한 집합체에 이르기까지 무엇이든 키와 값이 될 수 있다.
5)
스키마란 ?
데이터베이스의 구조와 제약 조건에 대하여 전반적인 명세를 기술한 것을 의미.
즉, 데이터베이스를 구성하는 자료 개체의 성질, 관계, 조작, 자료값 등의 정의를 총칭.
4. 관계형 데이터베이스
1)
관계형 데이터베이스는 실무에서 많이 사용하는 데이터베이스의 종류의 하나이다.
2)
관계형 데이터베이스는 데이터를 테이블 형태로 저장한다.
3)
관계형 데이터베이스는 데이터를
열(column, 속성, 필드, attribute) 과 행(row, tuple, record) 으로 구성한 테이블 이다.
PK는 각 행을 식별 하는 식별자 이다.

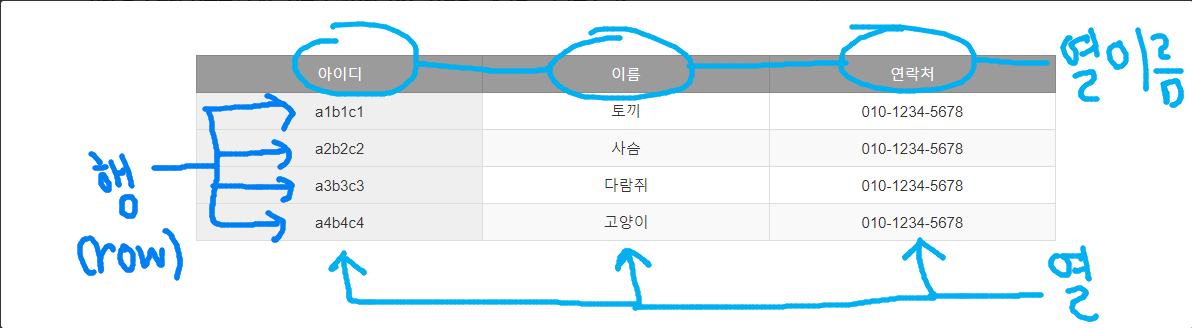
4)
관계형 데이터베이스의 필요성 및 장점

위와 같은 테이블이 있다.
열은, 주문 번호, 회원 이름, 회원 주소, 주문 상품, 배송 주소 이다.
이때, 만약에 곰 회원의 주소가 인천에서 수원으로 바뀐다면 ?
테이블에서 회원 이름이 곰인 데이터를 모두 찾아서 주소를 수원으로 수정하면 된다.

근데, 지금은 테이블 1개만 수정하면 되는 상황이고, 곰이라는 회원도 한명이라
수정 자체가 크게 어렵지는 않다.
하지만, 테이블이 주문 테이블이 아니라, 다른 테이블도 있다고 가정해보자.
가령,
장바구니 테이블, 쿠폰 테이블, 교환 테이블, 반품 테이블, 멤버쉽 테이블, 등등 ..
그러면, 모든 테이블의 곰이라는 회원을 찾아서 곰 회원의 주소를 수원으로 변경해야 하는
번거로움 및 실제로 반영하기 어려운 문제점이 생기게 된다.
>>
그래서 관계형 데이터베이스는 테이블을 분리하고 각 테이블 목적에 맞는 데이터만 저장 한다.
그리고 각 테이블을 참조 관계로 연결해서 이러한 문제를 해결한다.
>>
즉, 관계형 데이터베이스는 데이터의 중복을 추구하고, 이로인해 관리의 효율성을 얻게된다.
>>
위의 주문 테이블에서
회원 테이블과 주문 테이블로 분리 하여 회원 번호(PK) 로 회원 테이블과 주문 테이블을 연결한다.
[ 회원 테이블 ]
| 회원번호 | 회원 이름 | 회원 주소 |
| 1000 | 강아지 | 서울 |
| 1001 | 고양이 | 수원 |
| 1002 | 곰 | 인천 |
[ 주문 테이블 ]
| 주문 번호 | 회원 번호 | 주문 상품 | 배송 주소 |
| 100 | 1000 | 껌 | 서울 |
| 101 | 1001 | 츄르 | 수원 |
| 102 | 1002 | 연어 | 인천 |
이렇게 목적에 맞게 테이블을 분리하고 두 테이블을 참조 관계로 연결하면,
회원 주소가 변경되는 경우에 [ 회원 테이블 ] 만 수정하면 된다.
[ 주문 테이블 ] 은 회원 번호로 [ 회원 테이블 ] 의 데이터를 참조하므로,
[ 주문 테이블 ] 의 데이터는 변경하지 않아도 된다.
>>
이렇게 목적에 맞게 테이블을 분리하고 중복 데이터를 제거하는 과정을
정규화 라고 한다.
'Do it! SQL 입문 > 이론' 카테고리의 다른 글
| SQL 시작하기 (0) | 2023.06.15 |
|---|---|
| SQL 시작하기 (0) | 2023.06.15 |
| 데이터베이스와 SQL의 기초 (0) | 2023.06.11 |
| 데이터베이스와 SQL의 기초 (0) | 2023.06.11 |
| 데이터베이스와 SQL의 기초 (0) | 2023.06.11 |