1. 대량 데이터 발생에 따른 테이블 분할 개요
대량의 데이터가 존재 하는 테이블에는 많은 트랜잭션이 발생 하는데,
이때, 성능이 저하 되는 테이블 구조에 대해,
수평 / 수직 분할 설계를 통해 성능 저하를 예방 한다.
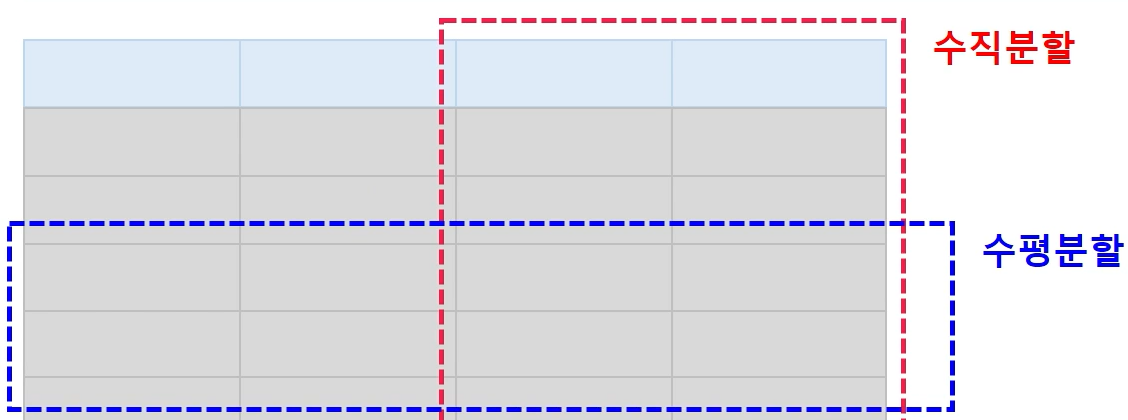
수직 분할 : 칼럼 단위로 분할 하여 I / O 를 감소 시킴.
수평 분할 : 로우 단위로 분할 하여 I / O 를 감소 시킴.
2. 테이블의 데이터는 블록 (Block) 단위로 저장 된다
오라클 기준으로, 하나의 블록의 크기는 8192 바이트 (B) 이다.
만약에 1 바이트 짜리 데이터를 읽더라도, 8191 바이트는 버려진다.
근데, 어떤 테이블에 칼럼이 엄청 많아서,
한개의 로우를 저장 할 때 8192 바이트를 초과 하면,
(이게 정확히 무슨 말인지 모르겠네)
한개의 로우를 저장 할 때, 여러 개의 블록에 데이터를 저장 하게 된다.
그러면, 한개의 행을 읽더라도 여러 개의 블록 데이터를 읽어야 하게 된다.
그렇다는것은, 해당 SQL 문의 블록 I / O 가 많아 진다는 것을 의미 한다.
3. 대용량 테이블에서 발생 할 수 있는 현상
- 로우 체이닝 (Row Chaining)
로우 길이가 너무 길어서, 데이터 블록 하나에 다 저장을 못해서, 두개 이상의 블록에 걸쳐서,
하나의 로우가 저장 되어 있는 형태.
- 로우 마이그레이션 (Row Migration)
데이터 블록에서 수정이 발생 하면, 수정된 데이터를 해당 데이터 블록 에서 저장 하지 못함.
다른 빈 공간의 블록을 찾아서 데이터를 저장 하는 방식.
- 로우 체이닝과 로우 마이그레이션이 발생 한다는 것 ?
많은 블록에 데이터가 저장 된다는 것을 의미 한다.
그렇다는것은, 데이터를 조회 할 때, 절대적인 블록 I / O 의 횟수가 증가 하게 된다.
이, 블록 I / O 의 횟수가 증가 한다는 것은, 디스크 (Disk) I / O 를 할 가능성도 높아 진다.
Disk I / O 를 하게 되면, 성능이 급격 하게 저하 된다.
[ 참고 ]
데이터 저장소 - Disk
메모리 - 버퍼 캐시
사용자 가 만약에 SQL 문을 입력 할 때, 메모리 내 (버퍼 캐시) 에 데이터가 존재 하면 빛의 속도로 결과를 출력 하는데,
버퍼 캐시에 데이터가 존재 하지 않으면, Disk (데이터 저장소) 에서 I / O 를 해서 결과를 받아야 한다.
그러면, 성능이 급격 하게 저하 되게 된다.
[ 참고 2 ]
만약에 한 테이블에 많은 수의 칼럼이 있다면 ?
- 칼럼 수가 많은 테이블을 SELECT 할 경우, Block I / O 의 수가 증가 한다.
- Block I / O 가 많아지면 자연스레 Disk I / O 양이 증가될 가능성이 높아 진다.
- Disk I / O 가 많아지면 성능이 급격 하게 저하 된다.
그래서 이렇게 지나치게 칼럼의 수가 많은 테이블은, 수직 분할 하면 성능이 향상 될 수 있다.
수직 분할 을 하면, 테이블을 어떤 기준으로 분리 했기 때문에, 칼럼 수가 상대적으로 적어져서,
로우 체이닝과 로우 마이그레이션이 많이 줄어 들 수 있게 된다.
[ 참고 3 ]
마찬가지로 한 테이블에 많은 수의 칼럼이 있다면 ?
수직 분할이 아닌, 수평 분할의 개념으로 테이블을 분리 시킬 수 있다.
수평 분할은 3가지 개념이 있다.
1) RANGE PARTITION
2) LIST PARTITION
3) HASH PARTITION
아래는 RANGE PARTITION 방법 이다. (레인지 파티션)

요금 테이블에 PK가 요금 번호 + 요금 일자로 구성 되어 있는데,
데이터 건수가 너무 ~~ 많다면,
하나의 테이블에 너무 많은 데이터가 존재 할테니까, 성능이 좋을 수가 없음.
그래서 이런 경우, 요금 특성상 월 단위로 데이터 처리를 해서, PK인 요금 일자의 년 + 월 로 해서,
12 개월로 나눠서 테이블 12 개를 파티션 한다.
그러면 데이터 보관 주기에 따라서 테이블에 데이터를 쉽게 조작 할 수 있기 때문에,
(파티션 테이블만 DROP 하면 되니까)
데이터 보관 주기에 따른 테이블 관리가 용이 하게 된다.
아래는 LIST PARTITION 방법 이다. (리스트 파티션)

고객 테이블에 만약에 데이터가 엄청 많은데,
그러면 지역을 나타내는 사업소 코드 별로 리스트 파티션을 할 수 있다.
그래서, 위의 이미지와 같이, 서울 / 인천 / 전북 / .. / 제주 로 테이블을 리스트 파티션을 해서,
서울 고객은 A 테이블에 다 모여 ~
인천 고객은 B 테이블에 다 모여 ~
이런식으로 테이블을 파티션 한다.
그러면 특정 기준에 따라 테이블을 파티션 했기 때문에 성능이 향상 된다.
그렇지만, RANGE PARTITION 처럼, 데이터 보관 주기에 따라 쉽게 삭제 하는 기능은 이용 할 수 없다는게 차이 이다.
아래는 HASH PARTITION 방법 이다. (해시 파티션)
해시 파티션은 지정된 해시 조건에 따라 해싱 알고리즘이 적용 되서 테이블이 분리 된다.
설계를 한 사람은 테이블에 데이터가 정확 하게 뭐가 들어 갔는지를 알 수 없는게 특징 이다.
성능 향상을 위해 사용 하고, 데이터 보관 주기에 따라 쉽게 삭제 하는 기능은 마찬가지로 이용 할 수 없다.
4. 테이블에 대한 수평 분할 / 수직 분할의 절차
1) 데이터 모델링을 완성 !
2) 데이터베이스 용량 산정 !
3) 대량 데이터가 처리 되는 테이블에서 트랜잭션 패턴을 분석 !
4) 칼럼 단위로 처리 되는지 ? 로우 단위로 처리 되는지를 분석 !
5) 데이터가 무엇을 기준으로해서 집중화된 단위로 데이터가 처리 되는지를 분석 해서 분리 검토 !
'SQLD > 데이터 모델과 성능' 카테고리의 다른 글
| 분산 데이터베이스와 성능 (0) | 2023.11.13 |
|---|---|
| 데이터베이스 구조와 성능 (1) | 2023.11.12 |
| 반정규화와 성능 (0) | 2023.11.10 |
| 정규화와 성능 (0) | 2023.11.10 |
| 성능 데이터 모델링의 개요 (0) | 2023.11.10 |



