예전에 HTTPS에 대해서 간단하게 정리했었는데,
https://hwanii96.tistory.com/453
HTTPS
1. HTTP 전송 정상적인 사용자에게 평문 (plaintext) 으로 암호화 하지 않은 중요한 정보를 전송 하게 될 때, 정상적인 사용자 입장에서는 빠르게 정보를 읽을 수 있기 때문에 좋다. 하지만, 보안에 취
hwanii96.tistory.com
이번에 SSL (Secure Sockets Layer) 과 TSL (Transport Layer Security) 에 대해 학습 하기 전에,
(SSL, TSL : 데이터를 암호화 하는 통신 프로토콜. 현재는 TSL을 사용 한다)
HTTP와 HTTPS에 대해서 상세하게 학습 해보려고 한다.
(HTTPS에 대한 내용은 다음 게시글에서 정리)
1. HTTP
HTTP (Hypertext Transfer Protocol) 는 웹에서 데이터를 주고 받기 위한 통신 규약 이다.
OSI (Open Systems Interconnection) 모델 에서 응용 계층 (Application Layer) 에 속한다.
(OSI 모델 : 네트워크 프로토콜 설계 및 통신을 기술 하기 위한 프레임워크. 7개의 계층으로 구성 되어 있다)
(각 계층은 특정 기능을 수행 하고, 상위 및 하위 계층과 통신하여 전체 통신 프로세스를 완성 한다)
응용 계층은 최종 사용자와 직접 상호 작용 하고, 응용 프로그램에 서비스를 제공 한다.
프로토콜 및 데이터 형식 변환, 사용자 인터페이스 등을 다룬다.
따라서, 응용 계층은 개발자 하고도 가장 밀접하게 연관 되어 있는 계층이라고 할 수 있다.
2. HTTP의 기본 특성
아래의 5가지 특성을 가지고 있다.
1) 요청 (request) / 응답 (response) 기반의 클라이언트 / 서버 구조 프로토콜
2) 미디어 독립적 프로토콜
3) 비연결성 프로토콜
4) 스테이트리스 프로토콜
5) 지속 연결 프로토콜
1) 요청 / 응답 기반의 클라이언트 / 서버 구조
- HTTP 클라이언트 (HTTP 요청 메세지를 보낸다)
- HTTP 서버 ( HTTP 응답 메세지를 보낸다 ( WAS, .. 등등 응답 메세지를 보내주는 주체가 되는 서버) )
[ 참고 ]
HTTP는 클라이언트와 서버 관계에서만 HTTP로 데이터를 주고 받을 수 있는 것은 아니다.
서버와 서버 관계에서도 HTTP 메세지를 주고 받을 수 있다.
HTTP는 웹에서 데이터를 주고 받기 위한 통신 규약 이므로,
당연하게도 서버와 서버 관계에서도 HTTP로 데이터를 주고 받을 수 있는 것이다.
만약에 A라는 서버와 B라는 서버가 있을 때, A가 B에게 HTTP 요청을 보내면,
A는 이 상황에서 클라이언트가 되고, B는 서버가 된다.
이렇게 응용 계층에서 데이터를 주고 받을 때, 오늘날은 대부분 HTTP를 이용 한다.
2) 미디어 독립적
- HTTP는 사실상 오늘날 응용 계층에서의 데이터 통신 전체를 주관 한다고 봐도 무방 하다.
- 어떤 형태의 데이터라도 모두 HTTP 메세지로 송수신이 가능하다.
(HTML, 이미지, JSON, XML, 파일, 영상, 등등 ..)
- HTTP 헤더 (Header) 를 통해서 어떤 형태의 데이터를 전송하는지를 명시할 수 있다.
3) 비연결성
- 구버전의 HTTP인 HTTP 1.0, HTTP 1.1, HTTP 2.0은 TCP 기반 이다.
(현재 HTTP는 3.0 까지 나와있고, 아직까지도 HTTP 1.1, 2.0 버전이 주로 사용 되고 있다)
- TCP는 연결성 프로토콜.
(OSI 모델에서 전송 계층에 속한다. 전송 계층 및 TCP에 대한 자세한 개념도 나중에 학습 예정)
(TCP : Transmission Control Protocol)
(HTTP는 TCP 위에서 동작 한다. TCP는 안정적이고 신뢰성 있는 데이터 전송을 위한 통신 규약 이다)
- 하지만, HTTP는 비연결성 프로토콜 이다.
HTTP가 연결성 프로토콜이면 안좋은 이유 !
>> 다수의 클라이언트가 연결을 시도할 경우, 연결을 유지하는 동안 서버의 자원 소모가 너무 크기 때문 !
예를들어, 수백 수천만의 클라이언트가 접속을 하는 상황 일 때,
이럴때마다 모두 3-way handshake를 하고, 연결을 수립 하고, 연결을 종료 한다면,
굉장히 많은 자원 소모가 발생할 수 밖에 없게 된다.
따라서 HTTP는 비연결성 프로토콜 일 수 밖에 없게 된다.
참고 : TCP 통신 연결 절차

4) 스테이트리스 (Stateless)
- 기본적으로 HTTP는 클라이언트의 상태를 기억 하지 않는다.
즉, 클라이언트가 어떤 상태였고, 클라이언트가 어떤 데이터를 보냈었는지를 기억 하지 않는다.
- 클라이언트는 하나의 서버에 종속될 필요가 없다.
- 여러 번 요청을 보내야 할 경우, 여러 서버에 요청할 수 있다.
- 만약에 HTTP가 스테이트풀 (Stateful) 프로토콜 이였을 경우 ???
>> 클라이언트는 한 서버에 종속될 수 있는 문제가 발생 한다.
예를들어, HTTP 서버가 다수 일 때, 클라이언트가 A 라는 서버에게 요청을 보내고 응답을 받았다고 가정 해보자.
이때, HTTP 프로토콜로 데이터를 주고 받았는데, HTTP가 스테이트풀 (Stateful) 프로토콜 이였다고 해보자.
그러면, 서버는 클라이언트의 상태를 모두 기억 하고 있게 된다.
그런데, 이때 서버에 문제가 생기면 어떻게 될까 ?
클라이언트는 문제가 발생한 A 서버 하고 통신을 더이상 하지 못하게 될 것이다.
즉, 그동안 통신을 주고 받았던 모든 상태가 날라 가게 된다.
따라서, HTTP가 클라이언트의 상태를 기억 하는 스테이트풀 프로토콜 이라면,
어떤 특정 서버에 종속될 수 있는 문제점이 발생할 수 있으므로, HTTP는 스테이트리스 해야 한다.
특정 서버에 종속될 수 있는 문제점이라는 것은 아래와 같은 상황이 발생 하면 더 큰 문제로 다가올 수 밖에 없게 된다.
서버의 IP가 변경된다던지,
요청을 보낸 서버가 고장난다던지,
서버가 여러 개가 있다면,
등등
클라이언트가 하나의 서버에 종속 되면 문제가 발생할 수 밖에 없게 된다.
5) 지속 연결 (Keep-Alive)
- 연결할 때마다 3-way handshake를 해야 할까 ?
>> 당연히 아니다.
혼잡도가 증가 하고, 매번 3-way handshake를 해야 하면 시간이 증가할 것이다.
>> 비효율.
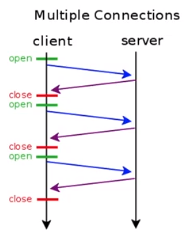
위의 이미지는 HTTP 메세지마다 연결을 열고 끊고 하는 상황 이다. (비효율)
즉, 지속 연결은 하나의 연결을 사용해 여러 개의 HTTP 요청 및 응답을 주고 받을 수 있는 것을 의미 한다.
== Keep-Alive
다시말해서, 한번 TCP (Transmission Control Protocol) 연결이 되었으면, 그 연결을 이용 해서 여러 번 연결 가능 !
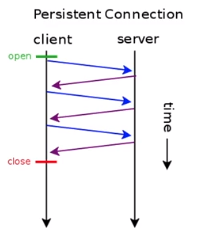
HTTP 메세지를 주고 받기 위해서 TCP 연결에 성공 하면, 연결을 끊지 않고 계속 연결이 가능 하다. (효율)
3. HTTP 버전별 특성
HTTP는 오늘날까지도 지속적으로 개발이 되고 있는 프로토콜 이다.
HTTP 0.9
HTTP 1.0
HTTP 1.1
HTTP 2.0
HTTP 3.0
위의 버전별 과정을 거쳐 왔다.
오늘날은 HTTP 1.1 하고, HTTP 2.0 을 많이 사용 한다.
HTTP 3.0 은 점점 점유율이 높아 지고 있다.
1) HTTP 0.9 Ver
단일한 요청 방법 (GET 메서드), 비지속 연결, 별다른 기능 X
2) HTTP 1.0 Ver
다양한 요청 방법 (메서드) 및 헤더 추가
3) HTTP 1.1 Ver
지속 연결 기능 추가 (Keep-Alive)

4) HTTP 2.0 Ver
요청 순서대로 응답을 반환 하지 않아도 됌.
헤더 압축.
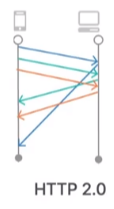
5) HTTP 3.0 Ver
UDP 기반 프로토콜인 QUIC로 변경.
기존 2.0 Ver 까지는 모두 TCP (Transmission Control Protocol) 기반 이였는데,
3.0 Ver 부터는 Google에서 개발한 QUIC는 UDP 기반의 프로토콜 이다.
4. HTTP 메세지의 구성 요소

HTTP 메세지는 기본적으로 위와 같이 구성 되어 있다.
HTTP-message는 4가지로 구성 되어 있다.
1) start-line
2) header-field CRLF (CRLF : 개행 줄바꿈을 의미)
3) CRLF (CRLF : 개행 줄바꿈을 의미)
4) message - body
아래에서 예시를 통해 확인 하기.

위의 이미지는 HTTP 요청 이다.
여기서 GET /restapi/v1.0 HTTP/1.1 부분이 start - line 이다.
( HTTP 메서드 (공백) 요청 대상 (공백) HTTP 버전 (개행 == 줄바꿈) )
Accept : application/json
Authorization : Bearer UExBMDFUMDRQV1MwMnzpdvtYYNWMSJ7CL8h ..
위와 같이 줄바꿈으로 다수의 데이터가 출력될 수 있는데, 이것을 헤더 (Header) 라고 한다.
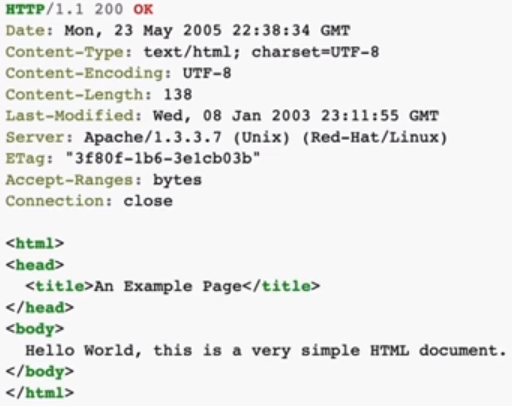
위의 이미지는 HTTP 응답 이다.
여기서,
HTTP/1.1 200 OK 부분이 start - line 이다.
( HTTP 버전 (공백) 응답 코드 (공백) 이유 문구 (개행 == 줄바꿈) )
HTTP 응답 헤더에서 제일 중요한 부분은 응답 코드 이다. (200대, 300대, 400대, 500대, ..)
Date: ~~~
Content-Type: ~~~
Content-Encoding: ~~~
Content-Length: ~~~
..
Connection: ~~~
가 헤더 (Header) 이다.
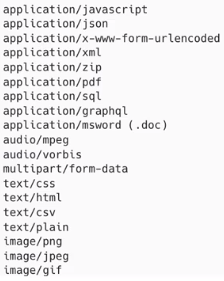
그리고, 줄바꿈 (CRLF) 한번이 되고, <html> .. </html> 태그가 작성 되어 있는 부분이 [ message-body ] 이다.
이 message-body에 들어가는 데이터는 위에서 정리했듯이, 여러 다양한 모든 데이터가 올 수 있다.
위의 예시에서는 HTML (Hyper Text Markup Language) 데이터 이지만, 그 외에 여러 다양한 데이터가 올 수 있다.
파일 이라던지, PDF 파일 이라던지, 이미지 파일 (JPG, PNG, ..) 이라던지, 미디어 파일 이라던지, JSON 데이터, ..
이런 특징을 HTTP의 기본 특성 중에서, 미디어 독립적인 특성이라고 했었다.
참고 : HTTP의 5가지 특성 중, 미디어 독립적 특성.

[ 참고 : HTTP 요청 헤더 예시 ]
HTTP 요청 헤더 - start line
( HTTP 메서드 (공백) 요청 대상 (공백) HTTP 버전 (개행 == 줄바꿈) )
예시)

즉,
GET 메서드 (공백) 요청 대상 (공백) HTTP 버전 (개행 == 줄바꿈) 의 형식 이다.
HTTP 요청 헤더에서 제일 중요한 정보는 HTTP 메서드 이다.
HTTP 메서드 : 서버에게 요청할 동작 (해당 자원으로 어떤 동작을 요청 할지 ?)
HTTP 메서드는 다양한 종류가 있지만, 아래는 대표적인 HTTP 메서드만 서술 한다.
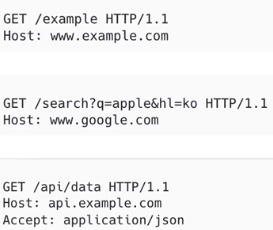
- GET : 자원 조회 (데이터 줘 !)
>> 리소스 조회에 사용 한다.
>> 일반적으로 쿼리 문자열을 사용 하고, 본문은 존재 하지 않는다. (본문을 억지로 넣을 수는 있지만, 그렇게 하지 않음)
>> 예시)
- POST : 요청할 데이터 처리 (이 데이터를 서버에서 처리 해줘 !)
>> 메세지 본문으로 처리할 데이터를 전송 한다. (우리가 제일 익숙한 form 태그로 특정 데이터를 submit 하는 상황)
>> 메세지 본문에 해당 하는 데이터를 처리하도록 요청 한다.
>> 데이터를 어떻게 처리할지는 서버가 결정 한다. (클라이언트 쪽에서는 데이터를 그냥 보내면 된다)
>> 예시)

- PUT : 자원 덮어쓰기
>> 자원이 있으면 본문으로 보낸 데이터로 완전히 대체.
>> 자원이 없으면 본문으로 보낸 데이터로 생성 한다.
>> 예시)
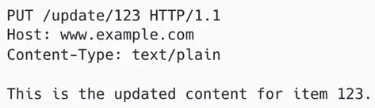
즉, 본문에 해당 하는 This is the updated content for item 123. 으로 대체 된다.
백엔드 서버 에서 저 해당 하는 본문의 데이터로 대체 되도록 로직이 구현 되어 있다.
- PATCH : 자원 특정 부분 변경
>> 예시)
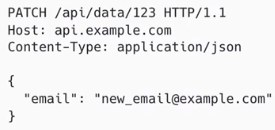
만약에 위와 같이 email 데이터만 본문으로 싣어서 보냈다면, 아래의 email 부분만 새롭게 변경 되는 것이다.

- DELETE : 자원 삭제
>> 예시)

이 외에도, HEAD, OPTIONS, TRACE, CONNECT 메서드가 존재 한다.
[ 요약 ]
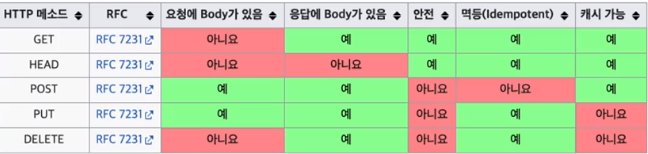
메서드가 안전한가 ?
>> 이 메서드를 수행 하면, 백엔드의 데이터 (자원)가 변경될 위험성이 있는가 ?
>> GET, HEAD는 데이터 변경이 아니기 때문에 안전 하다.
>> POST, PUT, DELETE는 데이터 변경 및 삭제 이기 때문에 안전 하지 않다.
먹등 (Idempotent) 이란 ?
>> 여러번 동일한 요청을 보내도 첫 요청과 결과가 같은가 ? 를 의미 한다.
>> GET은 여러번 요청을 해도 첫 요청과 결과가 같다.
>> PUT도 처음 데이터를 덮어 씌우고 이후에 첫 덮어 씌운 결과와 결과가 계속 동일 하다.
>> DELETE도 처음 데이터를 삭제한 이후, 삭제된 데이터의 결과는 이미 삭제된 데이터 이므로 변동성이 없다.
하지만, POST는 다르다.
예를들어, 어떤 댓글 또는 글을 작성 하고 저장 버튼을 클릭 했다.
이 저장 버튼 클릭 요청은 POST 요청이 될 것 이다.
이때, 이 요청을 100000만번 수행 됬다고 가정 해보자.
그러면, 100000만 개의 게시글 또는 댓글이 작성 되어 있을 것이다.
이것은 첫 요청과 동일한 결과가 아님을 의미 한다.
또한, 회원 가입을 시도할 때, 첫 회원 가입 이후, 여러 번의 회원 가입이 불가능 하다.
즉, 첫 요청의 결과와 같지 않다.
따라서, POST 방식은 여러번 동일한 요청을 보내도 첫 요청과 결과가 같지 않다.
[ 참고 2 ]
대표적인 헤더 정보
굉장히 다양하지만, 자주 보이는 것들로 정리.
기본적인 헤더 정보의 구조는 다음과 같다.

Host : 요청 호스트에 대한 호스트명 + 포트 정보 (요청을 보낸 URL)

Date : 메세지 생성 시간

Referer : 직전에 머물렀던 URL ( 이전에 참조했던 페이지 또는 리소스 (자원) )

User-Agent : 클라이언트 소프트웨어, 브라우저 명칭과 정보

Mozila : 접속한 브라우저가 Mozila와 호환.
Windows NT 10.0; Win64; x64 : 윈도우 10 버전의 64비트 X64 아키텍처 사용.
AppleWebKit : 브라우저를 렌더링 하는 Apple의 웹킷 엔진 사용.
Chrome, Safari : 브라우저 이름과 버전.
Server : 서버 소프트웨어 명칭과 정보
Connection : keep-alive (HTTP 1.1 이상 부터는 지속 연결 지원이 된다. 지속 연결 지원 여부를 알려주는 정보)

Location : 리다이렉트시 이동할 경로
Content-Type : HTTP 요청 및 응답에서 사용할 데이터의 타입


[ Reference ]
https://developer.mozilla.org/ko/docs/Web
개발자를 위한 웹 기술 | MDN
웹의 개방성은 개발자들에게 많은 기회를 제공합니다. 하지만 웹 기술을 잘 활용하려면 우선 그 사용 방법을 잘 알아야 합니다. 아래의 링크들을 확인하여 다양한 웹 기술을 배워보세요.
developer.mozilla.org
'개념 > Study' 카테고리의 다른 글
| SSL (Secure Sockets Layer) / TLS (Transport Layer Security) (0) | 2023.12.13 |
|---|---|
| HTTP vs HTTPS [2] & SSL (0) | 2023.12.12 |
| WebSEAL 서버와 BackEnd 서버의 데이터 교환 방법 (2) | 2023.12.08 |
| DB2 설치 하기 (2) | 2023.12.03 |
| MobaXterm 설치 (0) | 2023.12.03 |



